Working with Null and Sparse Data#
Objectives#
Definitions & Understanding of what sparse data are, how to use them with a
Trainee, and how prediction performance changes as data sparsity increases.
Prerequisites#
You have successfully installed Howso Engine
You have an understanding Howso’s basic workflow.
Concepts & Terminology#
This guide focuses primarily on the concept of sparse data. We additionally recommend being familiar with the following concepts:
Sparse Data#
The term sparse data usually refers to data which consist of primarily zeroes, with few values being nonzero. While Howso Engine has no trouble with these sorts of data, this article is primarily concerned with data that are sparse in that the data contain missing values. For example,
How-To Guide#
Howso Engine handles sparse and missing data without any extra setup. Simply train() your data, with or without missing values, and the
Engine will handle them. There is no need to preprocess missing data and, in fact, preprocessing missing data may harm predictive power or robustness
to unseen data. As such, we recommend performing no preprocessing if possible.
Note
Preprocessing may be warranted if missing values are used to represent something with specific meaning in your dataset. In that instance, it would be best to replace missing values that abide by this representation with a non-missing value and leave any values which are truly missing as they are.
What a Missing Value Means#
When computing similarity between cases, a missing value is considered to be of maximal Uncertainty for that feature. This is true even if both cases have missing values in the same place. After all, \(NaN \neq NaN\). As mentioned above, if the data you are working with contain missing values that represent something specific, those should be changed from missing values to something else. If we were to treat those values as missing, matches would not be considered similar and may therefore harm predictions in that instance.
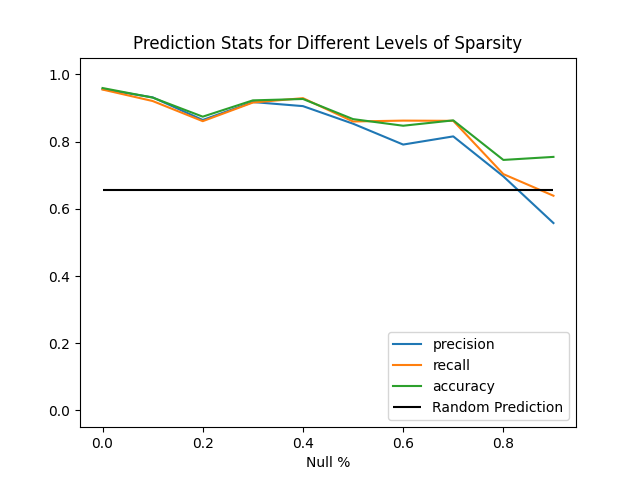
How Well are Sparse Data Handled#
As shown in the Sparse Data Prediction recipe, we maintain high degrees of accuracy even as
large percentages of the data are replaced with missing values.
Outputting Missing Values#
In order to output missing values, the allow_null feature attribute must be set in the bounds of that feature. If this is set, both
discriminative and generative react() s can output missing values. This can be set using /basics/feature_attributes().
features = infer_feature_attributes(
df,
features={"Clump_Thickness": {"bounds": {"allow_null": True}}}
)
trainee = Trainee(features=features)
trainee.train(df)
trainee.react(contexts=contexts, action_features=action_features)
API References#
howso.utilities.infer_../basics/feature_attributes()